





什么是实时抓取固定网页数据
实时抓取固定网页数据是指通过特定的技术手段,自动地从互联网上的固定网页中提取和获取数据的过程。这种技术广泛应用于数据监控、市场分析、舆情监测等领域。实时抓取固定网页数据可以帮助企业和个人快速获取关键信息,提高决策效率。
实时抓取固定网页数据的重要性
在信息爆炸的时代,实时获取和分析数据变得尤为重要。以下是一些实时抓取固定网页数据的重要性:
市场分析:通过实时抓取竞争对手的网页数据,企业可以快速了解市场动态,调整市场策略。
舆情监测:实时抓取社交媒体、新闻网站等平台的数据,可以帮助企业及时了解公众对品牌或产品的看法,及时应对舆情。
数据监控:对于金融市场、能源市场等,实时抓取相关网页数据可以帮助投资者及时做出交易决策。
科学研究:科研人员可以通过实时抓取相关网页数据,获取最新的研究进展和成果。
实时抓取固定网页数据的技术方法
实时抓取固定网页数据通常涉及以下几种技术方法:
网页爬虫(Web Crawler):通过编写爬虫程序,自动访问目标网页,提取所需数据。
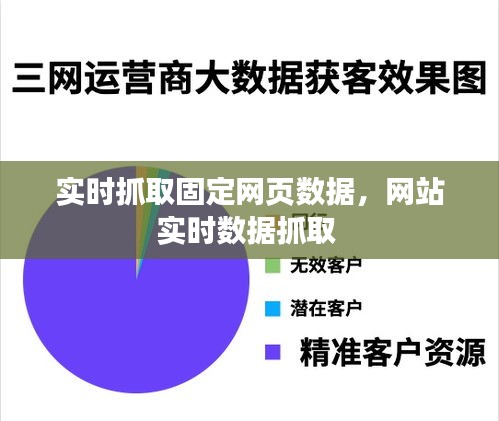
网络爬虫(Network Crawler):与网页爬虫类似,但可以访问更深层次的网页内容。
API(Application Programming Interface):通过调用第三方提供的API接口,获取网页数据。
数据挖掘(Data Mining):从大量数据中挖掘出有价值的信息。
实时抓取固定网页数据的挑战
虽然实时抓取固定网页数据具有很多优势,但在实际操作中也会面临一些挑战:
法律和伦理问题:在抓取数据时,需要遵守相关法律法规,尊重个人隐私。
数据质量:网页数据可能存在不准确、不完整等问题,需要通过数据清洗和验证来提高数据质量。

技术实现:实时抓取固定网页数据需要一定的技术能力,包括编程、网络知识等。
资源消耗:大规模的数据抓取和存储需要消耗大量计算资源和存储空间。
实时抓取固定网页数据的最佳实践
为了有效地进行实时抓取固定网页数据,以下是一些最佳实践:
合理规划数据抓取策略:根据需求确定抓取频率、数据范围等。
选择合适的抓取工具:根据项目需求选择合适的爬虫工具或API服务。
遵守法律法规:确保数据抓取行为符合相关法律法规和道德规范。
数据清洗和验证:对抓取到的数据进行清洗和验证,确保数据质量。
数据存储和备份:合理规划数据存储和备份策略,确保数据安全。
总结
实时抓取固定网页数据是一种高效的数据获取方式,可以帮助企业和个人快速获取关键信息。然而,在实际操作中,需要充分考虑法律、技术、数据质量等方面的因素。通过遵循最佳实践,可以最大限度地发挥实时抓取固定网页数据的价值。
转载请注明来自中蚨科技,本文标题:《实时抓取固定网页数据,网站实时数据抓取 》



 京ICP备16057535号-1
京ICP备16057535号-1